WildActor
Unconstrained Identity-Preserving Video Generation
†Corresponding author









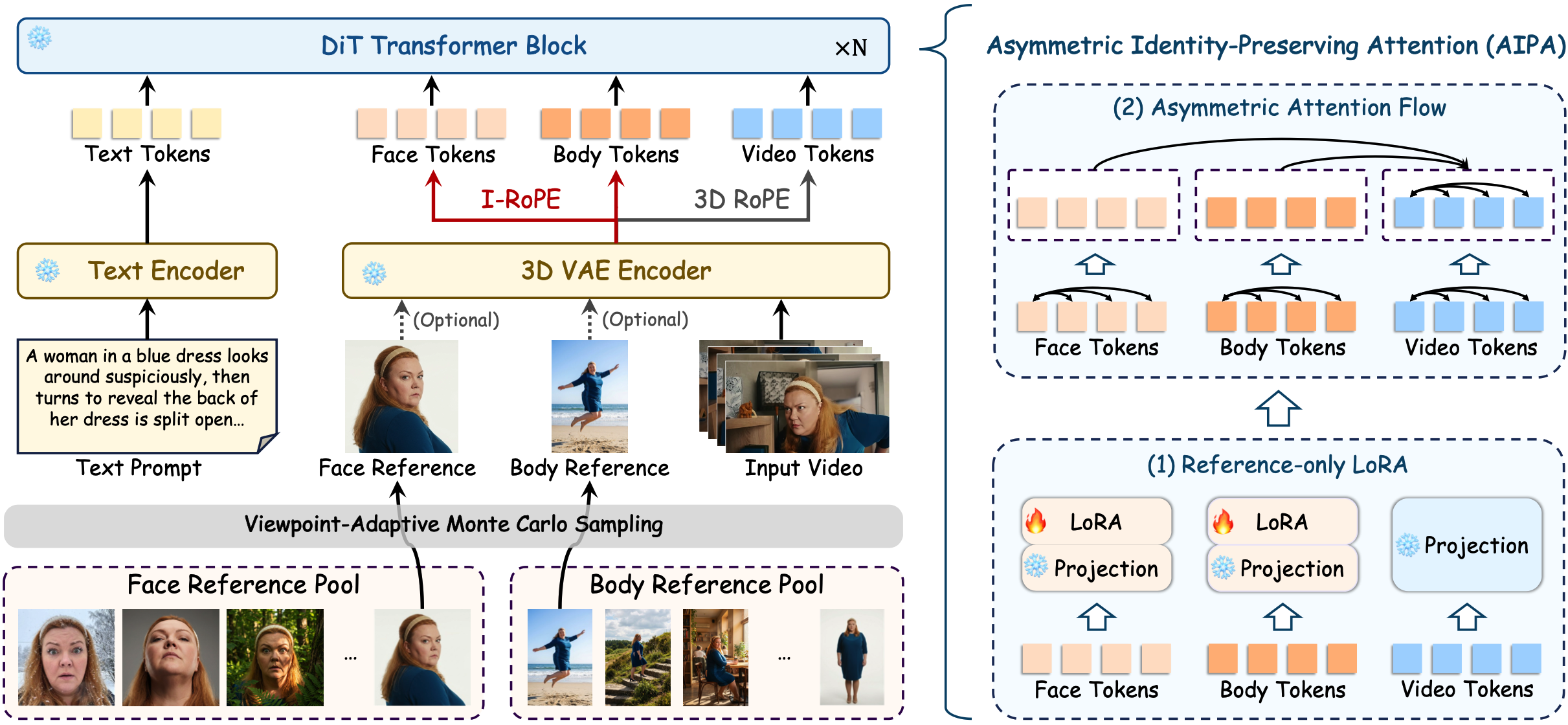
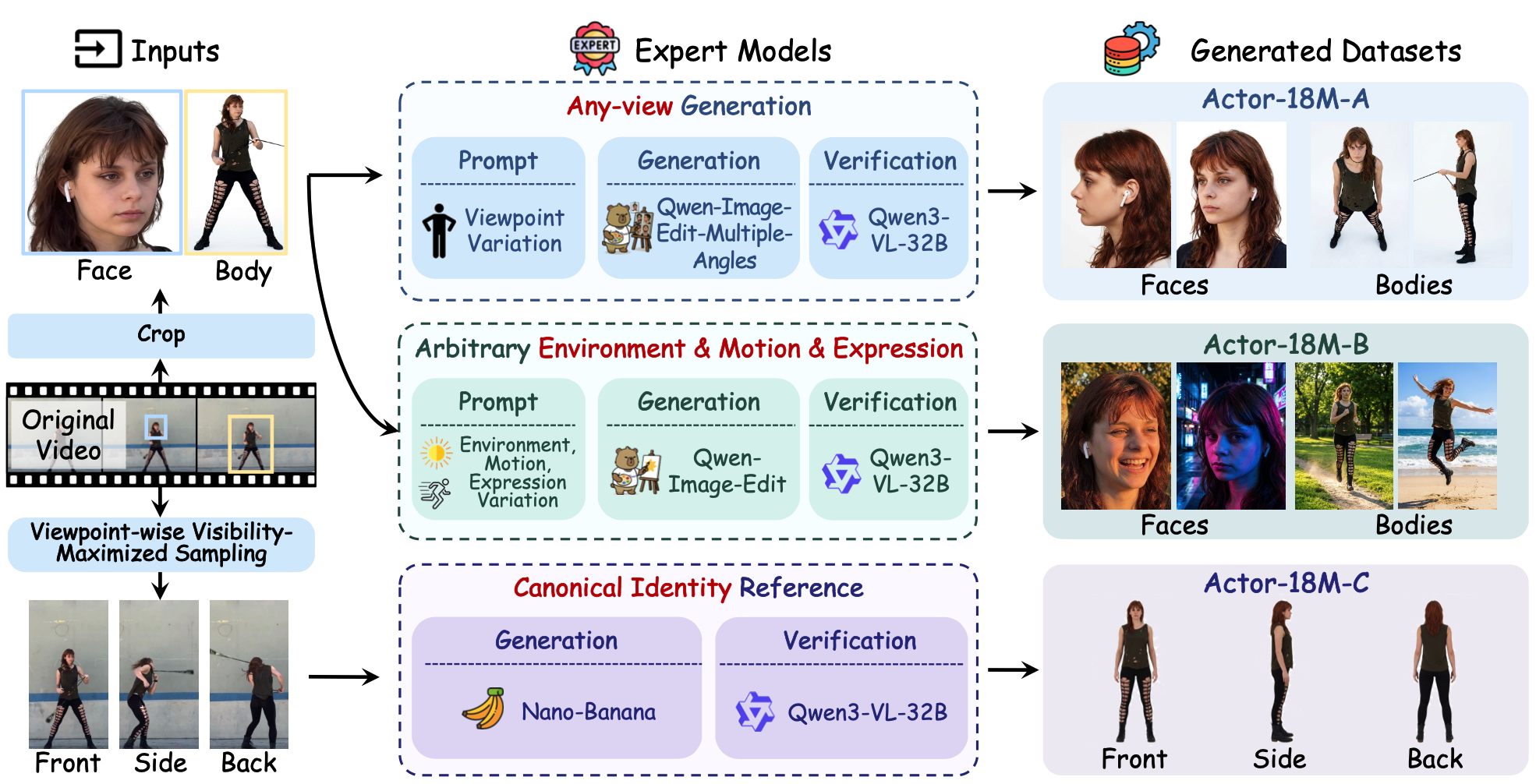
Actor-18M is the largest human-centric video dataset (1.6M videos / 18M images) constructed to capture view-invariant identity:
@article{guo2026wildactor,
title={WildActor: Unconstrained Identity-Preserving Video Generation},
author={Guo, Qin and Yang, Tianyu and He, Xuanhua and Shen, Fei and Zhang, Yong and Kang, Zhuoliang and Wei, Xiaoming and Dan Xu},
year={2026},
journal={arXiv preprint}
}